
La IA como ChatGPT es posible gracias al uso indiscriminado del contenido online. Cloudflare acaba de decir que se acabó
Publicado el 01/07/2025 por Diario Tecnología Artículo original

Las grandes IAs que usamos a diario como GPT, Gemini, Claude, Perplexity y compañía existen y son capaces de hacer lo que hacen gracias, en gran parte, al contenido disponible en Internet. Las empresas como OpenAI, Google y Anthropic, por mencionar algunas, han rastreado (y rastrean en tiempo real) la web en busca del contenido que da respuesta a las preguntas del usuario.
Y lo hacen, salvo que haya acuerdos específicos, sin ofrecer una contraprestación a los creadores de dicho contenido más allá de un enlace. Es una práctica que lleva en tela de juicio desde el nacimiento de esta tecnología. Artículos de blogs, WikiPedia, libros, contenido generado por el usuario, hasta datos personales. Los rastreadores, esos bots automatizados, no se dejan nada atrás y hoy Cloudflare ha dicho que se acabó
Desde hoy, Cloudflare bloqueará por defecto los scrapers de IA, algo que tiene más implicaciones de lo que podría parecer. Empecemos por el principio.
Web crawlers. Esta tecnología no es nueva y, de hecho, es gracias a ella que los cimientos en los que se basa Internet (la búsqueda web) existan. Seguramente resulte familiar lo de "la araña de Google", ese bot que rastrea toda la web en busca de contenido que indexar y ofrecer al usuario. Pues es solo uno de los miles y miles que hay y que generan el 30% de todo el tráfico a nivel mundial.
Esta tecnología fue capital para darle forma al Internet que conocemos y la relación con los generadores de contenido era simbiótica. Nacía la economía del clic: el creador genera un contenido, Google lo indexa, el usuario lo encuentra a través de Google, Google genera ingresos con la publicidad del buscador, el creador recibe tráfico gratis y genera ingresos gracias a la publicidad, los afiliados, etc.
Con la IA, la película es bastante diferente.
Datos. Los modelos de IA necesitan información para alimentarse, ser entrenados y ser capaces de responder preguntas. Para ello, las grandes empresas que todos conocemos rastrearon la web, extrajeron todo el contenido que pudieron y lo usaron para desarrollar tecnologías como ChatGPT. ¿Cuál es el problema? Que ese contenido podría estar protegido por derechos de autor, lo que llevó a que The New York Times demandase a OpenAI por este mismo motivo y a que las empresas de IA tuvieran que firmar acuerdos con los medios para poder acceder a su contenido.
 Image: Solen Feyissa
Image: Solen Feyissa
IAs conectadas. La IA fue evolucionando y, como era de esperar, se acabó conectando a Internet. Ya no solo daba respuestas en base a unos datos de entrenamiento finitos, sino que se podía conectar a la red para buscar la respuesta en los medios, blogs y páginas online en tiempo real (o casi en tiempo real). El usuario ya no tenía que hacer clic en un link. La IA buscaba, analizaba y generaba la respuesta, haciendo que el tráfico hacia los medios y blogs cayese.
A esta tecnología le dan vida los AI Crawlers o lo que es lo mismo: los rastreadores IA. Son la digievolución de los bots que dieron forma al Internet que conocemos. Entre ellos están GPTBot de OpenAI, Meta-ExternalAgent de Meta, ClaudeBot de Anthropic o ByteSpider de ByteDance. Con ellos empieza a deteriorarse la relación simbiótica que comentábamos anteriormente porque el usuario ya no accede al contenido original, no hace click. En su lugar, consume un producto derivado generado por IA.
El mayor ejemplo: las nuevas vistas previas generadas con IA que aparecen en Google cada vez que haces cualquier búsqueda.
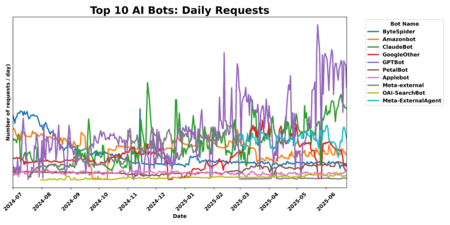 Volumen de peticiones diarias de los principales AI bots | Imagen: Cloudflare
Volumen de peticiones diarias de los principales AI bots | Imagen: Cloudflare
Echa el freno... O no, solo soy un .txt. ¿Cómo solucionar este rastreo indiscriminado y sin contraprestación? La primera propuesta fue actualizar el archivo robots.txt para indicarle a los bots que no pueden extraer el contenido de una web. Este archivo e uno de los recursos más usados para administrar la actividad de los bots, pero tiene un pequeño gran problema: su cumplimiento es voluntario. Las empresas de IA pueden seguir las instrucciones, o pueden ignorarlas y extraer el contenido.
Además, puede pasar que toquemos lo que no debemos y que nuestra web desaparezca de Google. Toda web que quiera estar en Google debe permitir que GoogleBot, su araña, para indicarle a los bots que no pueden extraer el contenido de una web. Este archivo es uno de los recursos más usados para administrar la actividad de los bots, pero tiene un pequeño gran problema: su cumplimiento es voluntario. Las empresas de IA pueden seguir las instrucciones, o pueden ignorarlas y extraer el contenido.remenda, como se puede deducir.s

Cloudflare se planta. Llegamos así al reciente anuncio hecho por Cloudflare. La plataforma (de la que depende medio Internet) ha anunciado que, desde hoy, el bloqueo de los AI Crawler estará activo por defecto. Para ello, Cloudflare ofrece una gestión directa de los robots.txt para evitar problemas como el mencionado anteriormente. La clave, claro, es que Cloudflare se encargará de mantener los bloqueos actualizados según avance el panorama de la IA. Esto, aunque se activa desde ya por defecto, es voluntario y se puede desactivar por completo en los ajustes.
A pagar. La otra propuesta de Cloudflare es Pay Per Crawl. Ya que la IA va a seguir necesitando acceso al contenido de una web, ¿por qué no darle al creador la opción de cobrar por dicho acceso? Pay Per Crawl, que está actualmente en beta, permite a los propietarios de dominios definir un precio fijo por solicitud. Si un AI Crawler quiere extraer el contenido de ese dominio, tendrá que pagar por él. Sobre el papel, esta herramienta tiene el potencial de cambiar el panorama actual, pero todo dependerá del alcance que tenga, su adopción y de qué medidas tomen los operadores de rastreadores.
Imagen de portada | Solen Feyissa
En Xataka | Le he preguntado a la IA cualquier chorrada y ahora estoy escribiendo una noticia sobre ella
utm_campaign=01_Jul_2025"> Jose García .