
Alibaba acaba de demostrar que OpenAI se gasta 78 millones en hacer lo mismo que ellos por 500.000 dólares
Publicado el 15/09/2025 por Diario Tecnología Artículo original

Hay una nueva técnica estrella para entrenar modelos de IA de forma súper eficiente. Es al menos lo que parece haber demostrado Alibaba, que el viernes presentó su familia de modelos Qwen3-Next y lo hizo presumiendo de una eficiencia espectacular que incluso deja atrás a la que logró DeepSeek R1.
Qué ha pasado. Alibaba Cloud, la división de infraestructura en la nube del grupo Alibaba, presentó el viernes una nueva generación de LLMs que calificó como "el futuro de los LLMs eficientes". Según sus responsables, estos nuevos modelos son 13 veces más pequeños que el modelo más grande que ha lanzado esa empresa, y que se presentó justo una semana antes. Puedes probar Qwen3-Next en la web de Alibaba (recuerda elegirlo del menú desplegable, en la parte superior izquierda).

Qwen3-Next. Así se llaman los modelos de esta familia, entre los que destaca especialmente Qwen3-Next-80B-A3B, que según los desarrolladores es hasta 10 veces más rápido que el modelo Qwen3-32B que se lanzó en el mes de abril. Lo realmente destacable es que además logra ser mucho más rápido con una reducción del 90% en los costes de entrenamiento.
500.000 dólares no es nada. Según el AI Index Report de la Universidad de Stanford, para entrenar GPT-4 OpenAI invirtió 78 millones de dólares en cómputo. Google se gastó aún más en Gemini Ultra, y según ese estudio la cifra ascendió a 191 millones de dólares. Se estima que Qwen3-Next solo ha costado 500.000 dólares en esa fase de entrenamiento.
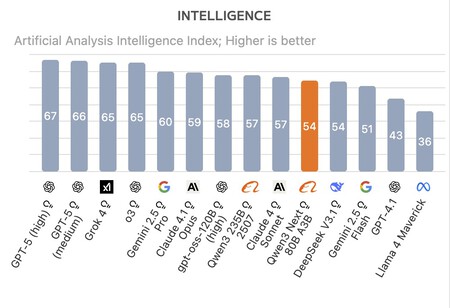
Mejor que sus competidores. Según los benchmarks realizados por la firma Artificial Analysis, Qwen3-Next-80B-A3B ha logrado superar tanto a la última versión de DeepSeek R1 como a Kimi-K2. El nuevo modelo de razonamiento de Alibaba no es el mejor en términos globales —GPT-5, Grok 4, Gemini 2.5 Pro Claude 4.1 Opus lo superan— pero aun así logra un rendimiento sobresaliente teniendo en cuenta su coste de entrenamiento. ¿Cómo lo ha hecho?
Mixture of Experts. Estos modelos hacen uso de la arquitectura Mixture of Experts (MoE). Con ella se "divide" el modelo en una especie de subredes neuronales que son los "expertos" especializados en subconjuntos de datos. Alibaba en este caso aumentó el número de "expertos": mientras que DeepSeek-V3 y Kimi-K2 hacen uso de 256 y 384 expertos, Qwen3-Next-80B-A3B hace uso de 512 expertos, pero solo activa 10 al mismo tiempo.
Atención híbrida. la clave de esa eficiencia está en la llamada atención híbrida. Los modelos actuales suelen ver reducida su eficiencia si la longitud de las entradas es muy larga y tienen que "prestar más atención" y eso implica más cómputo. En Qwen3-Next-80B-A3B se hace uso de una técnica llamada "Gated DeltaNet" que desarrollaron y compartieron el MIT y NVIDIA en marzo.
Gated DeltaNet. Esta técnica mejora la forma en la que presta atención los modelos al realizar ciertos ajustes a los datos de entrada. La técnica determina qué información retener y cuál se puede descartar. Eso permite crear un mecanismo de atención preciso y súper eficiente en coste. De hecho, Qwen3-Next-80B-A3B es comparable al modelo más potente de Alibaba, Qwern3-235B-A22B-Thinking-2507.

Modelos eficientes y pequeños. Los crecientes costes de entrenar nuevos modelos de IA empiezan a ser preocupantes, y eso ha hecho que cada vez más vamos esfuerzos para crear modelos de lenguaje "pequeños" que sean más baratos de entrenar, estén más especializados y sean especialmente eficientes. El mes pasado Tencent presentó modelos por debajo de los 7.000 millones de parámetros, y otra startup llamada Z.ai publicó su modelo GLM-4.5 Air con tan solo 12.000 millones de parámetros activos. Mientras, los grandes modelos como GPT-5 o Claude usan muchos más parámetros, lo que hace que el cómputo necesario para usarlos sea mucho mayor.
utm_campaign=15_Sep_2025"> Javier Pastor .